Implement External Datasource
LLMStack supports adding an external datastore as a read-only datasource. Adding an external datastore enables you to query the datastore and use the results in your LLM applications. LLMStack utilizes SQLAlchemy and currently supports MySQL, PostgreSQL, and SQLite dialects.
Adding any other SQLAlchemy-supported database dialect as an external datasource is straightforward. You can check out the implementations for PostgreSQLConnection, MySQLConnection, and SQLDatabaseSchema here.
Define Database Handler Connection Schema
Begin by defining the database connection schema. Define the schemas in the sql.py file using Pydantic for schema definitions. Ensure your schema definition class inherits from DataSourceSchema found in llmstack.datasources.handlers.datasource_processor.
In our example PostgreSQL implementation, we define the connection schema and add it to the SQLConnection union as follows:
from llmstack.common.blocks.base.schema import BaseSchema as _Schema
from llmstack.common.blocks.data.store.database.constants import DatabaseEngineType
from llmstack.datasources.handlers.datasource_processor import DataSourceSchema
class PostgreSQLConnection(_Schema):
engine: Literal[DatabaseEngineType.POSTGRESQL] = DatabaseEngineType.POSTGRESQL
host: str = Field(description="Host of the PostgreSQL instance")
port: int = Field(
description="Port number to connect to the PostgreSQL instance",
)
database_name: str = Field(description="PostgreSQL database name")
class Config:
title = "PostgreSQL"
class MySQLConnection(_Schema):
engine: Literal[DatabaseEngineType.MYSQL] = DatabaseEngineType.MYSQL
host: str = Field(description="Host of the MySQL instance")
port: int = Field(
description="Port number to connect to the MySQL instance",
)
database_name: str = Field(description="MySQL database name")
class Config:
title = "MySQL"
class SQLiteConnection(_Schema):
engine: Literal[DatabaseEngineType.SQLITE] = DatabaseEngineType.SQLITE
database_path: str = Field(description="SQLite database file path")
class Config:
title = "SQLite"
SQLConnection = Union[PostgreSQLConnection, MySQLConnection, SQLiteConnection]
class SQLDatabaseSchema(DataSourceSchema):
connection: Optional[SQLConnection] = Field(
title="Database",
# description="Database details",
)
connection_id: Optional[str] = Field(
widget="connection",
advanced_parameter=False,
description="Use your authenticated connection to the database",
# Filters is a list of strings, each formed by the combination of the connection attributes 'base_connection_type', 'provider_slug', and 'connection_type_slug', separated by '/'.
# The pattern followed is: base_connection_type/provider_slug/connection_type_slug. We may skip provider_slug or connection_type_slug if they are not present in the filter string.
filters=[ConnectionType.CREDENTIALS + "/basic_authentication"],
)
The above schema will be used to render the UI for the user to enter the connection details.
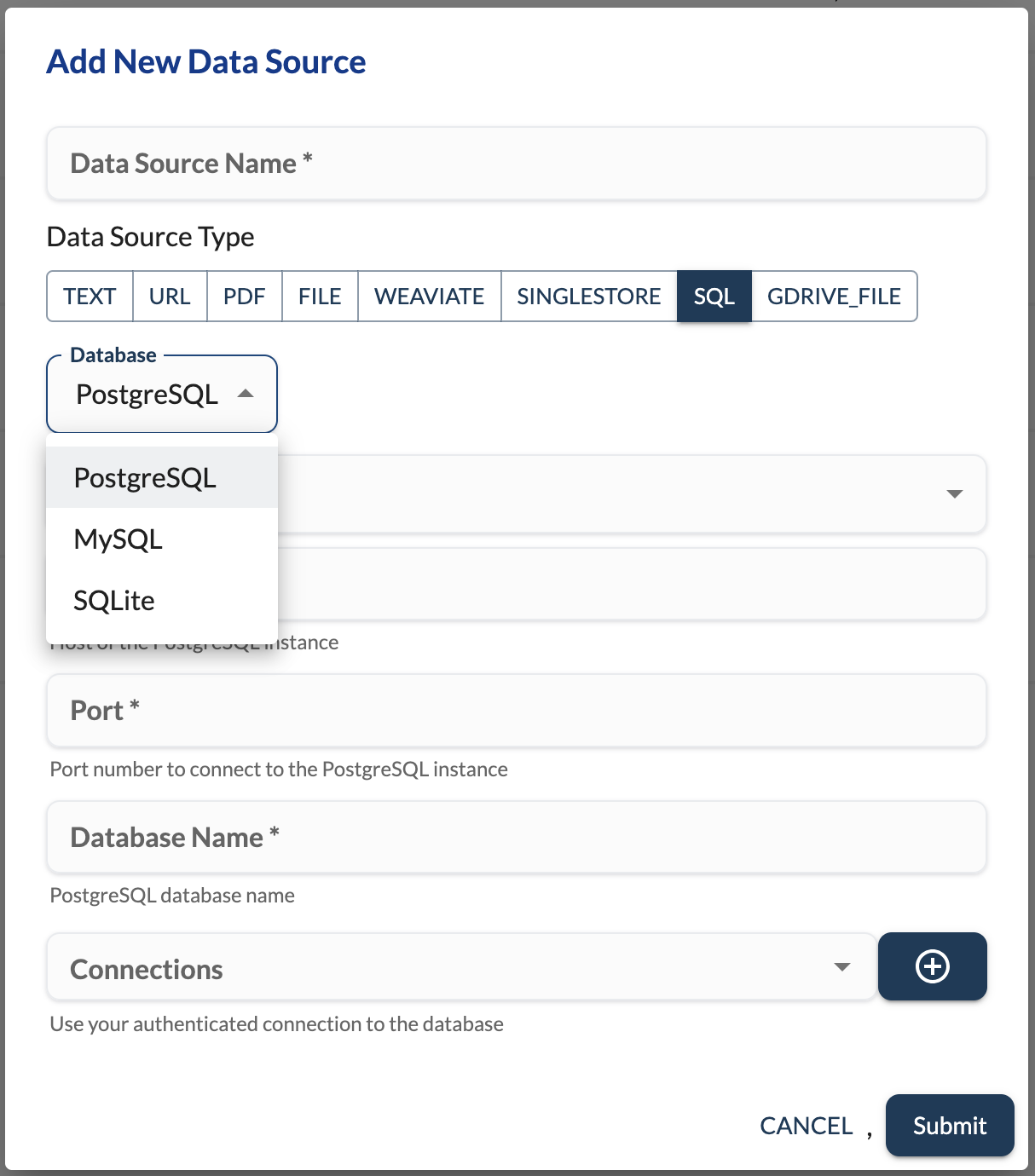
LLMStack framework ensures the connection details are securely stored in the database, either in an encrypted format or as plain text, depending on your configuration. To define this behavior, you also need to define a ConnectionConfiguration class, which will inherit from Config in llmstack.common.utils.models.
from typing import Optional, Dict
from llmstack.common.utils.models import Config
class SQLConnectionConfiguration(Config):
config_type: Optional[str] = "sql_connection"
is_encrypted = True
config: Optional[Dict]
The database connection details will be stored under the config key and will be encrypted if is_encrypted is set to True.
Define Database Handler Implementation
Once the schemas are defined, you can start using the SQLDataSource database handler implementation. As outlined below, it extends from DataSourceProcessor.
from llmstack.datasources.handlers.datasource_processor import DataSourceProcessor
class SQLDataSource(DataSourceProcessor[SQLDatabaseSchema]):
# Implementations follow
Like SQLDataSource, every DataSourceProcessor implementation must implement the following methods:
def __init__(datasource: DataSource)) :
The constructor will be passed the DataSource object. You can use the datasource object to access the database related configuration. The configuration will be available in the data key of the datasource.config object.
You can access the database connection object as follows:
config_dict = SQLConnectionConfiguration().from_dict(
self.datasource.config,
self.datasource.profile.decrypt_value,
)
self._configuration = SQLDatabaseSchema(
**config_dict["config"],
)
You can intialize you class as required from the connection dictionary as passed above.
def name() :
Define a name for your implementation. This name will be used to identify the datasource connection type. This will be displayed in the UI.
def slug() :
Define a slug for your implementation. This slug will be used to identify the datasource connection type.
def description() :
Provide a helpful description for your implementation. This will be displayed in the UI.
def provider_slug()
Provide a vendor slug for your database. Make sure this is unique, you can use the database provider/company name here.
def process_validate_config() :
When a user tries to add an external database, this method will be called with the details that the user provides. You can use this method to validate the connection details provided by the user. You can raise an exception if the connection details are invalid. Make sure this method returns a instance of your ConnectionConfiguration class.
def similarity_search()
Depending on your underlying database, you can implement a similarity search method. This method will be called when a user tries to search for a record in the database. You can use this method to search for similar records in the database and return the results.
def hybrid_search()
Depending on your underlying database, you can implement a hybrid search method. This method will be called when a user tries to search for a record in the database. You can use this method to search for similar records in the database and return the results.
If your underlying database does not support similarity search or hybrid search, you can simple implement a single search method and call that from both the similarity_search and hybrid_search methods. Implementing both the methods is required. The methods will be passed in the search query that user has entered. The methods should return a list of Document objects.
e.g [Document(page_content_key='content', page_content=str(<database-records>), metadata={'score': 0, 'source': self._source_name})]
Here page_content will contain you records retrieved from the datbase. This can be list of csv values or a json object serialized as string.