Build Generative AI Apps with Ollama and Llama3
Llama3 is an open source model from Meta that offers a great alternative to proprietary models like GPT-4. It is a large language model that can be fine-tuned on your own data to generate text / code. Ollama is a platform to run large language models locally. By combining Llama3 and Ollama, we can build powerful generative AI applications that run locally and are privacy friendly.
In this guide, we will see how to use Ollama with Promptly / LLMStack to build generative AI applications. By building this on LLMStack, you can run the application locally and have full control over the data and the model.
For this example, we will run llama3:latest model from Meta on Ollama and use LLMStack to build a simple recipe generator application. The application will take a request for recipe from the user and generate a recipe using the llama3 model.
If you want to use LLMStack to run everything locally, you can find LLMStack installation instructions here.
Install Ollama
Follow the instructions at Ollama to install Ollama on your machine.
Run Llama3 on Ollama
Once you have Ollama installed, you can pull the llama3 model on Ollama using the following command:
ollama pull llama3:latest
Ollama will download the llama3 model and make it available for use. It exposes a OpenAI compatible API at http://host.docker.internal:11434/v1/ by default. Please see https://github.com/ollama/ollama/blob/main/docs/faq.md for more details on how to use the API.
Configure Llama3 in LLMStack
In Promptly and LLMStack, one can use OpenAI API compatible inference endpoints with processors under OpenAI provider. To use the llama3 model on Ollama, you can configure OpenAI provider configuration in settings and provide the OpenAI compatible endpoint URL and model name from Ollama. When this model name is used in the ChatGPT processor, it will use the llama3 model on Ollama.
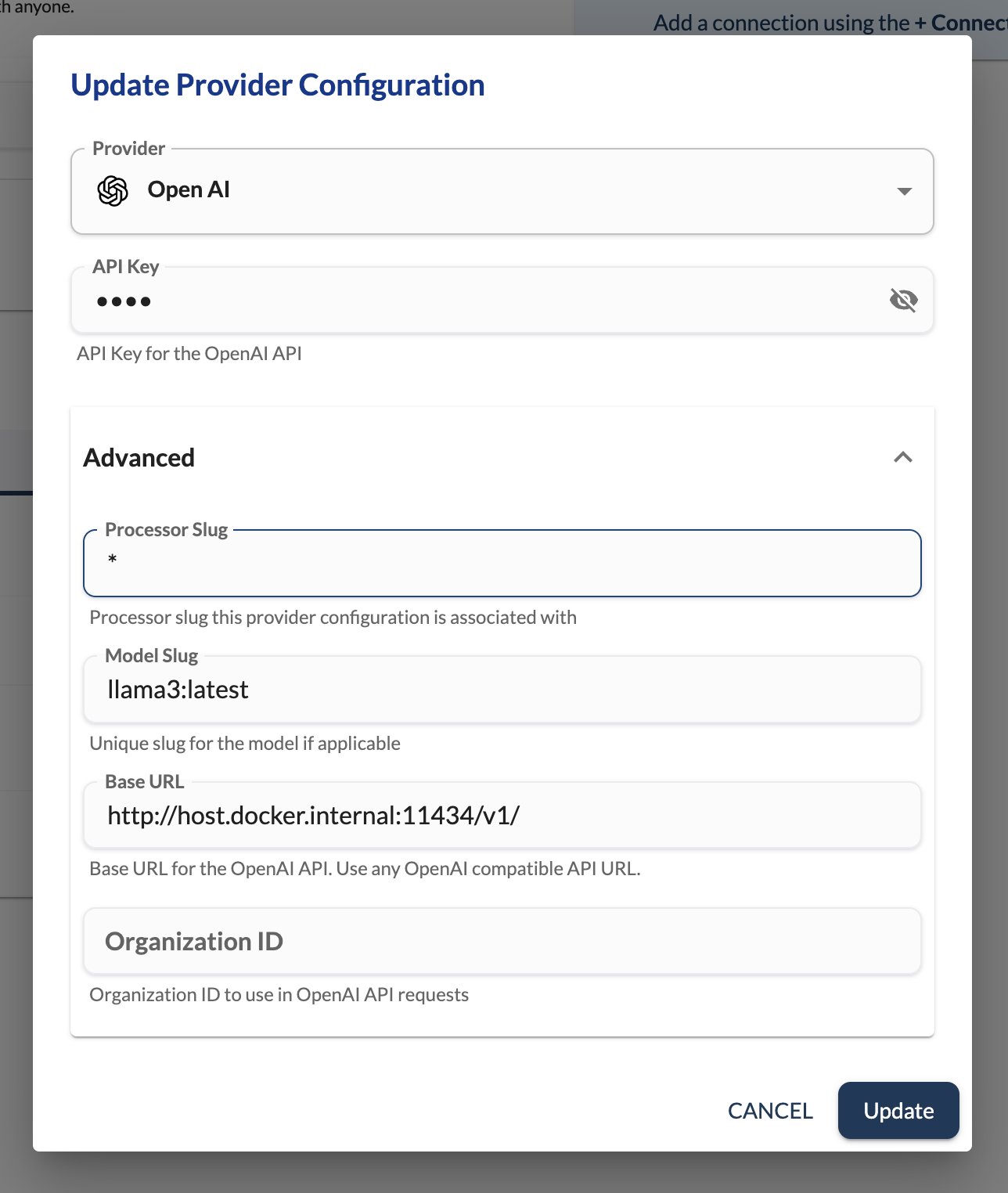
To configure the llama3 model on Ollama in LLMStack, click on Add Provider and select OpenAI as provider in the Providers section and provide the following details:
- Model Slug:
llama3:latest - Base URL:
http://host.docker.internal:11434/v1/ - API Key:
ollama-api-key
Make sure to use a non-empty API key for API Key field even if Ollama does not require it.
To test that the llama3 model is working correctly, you can use the Playground in Promptly / LLMStack to test the model. Go to Playground and select the OpenAI provider and ChatGPT processor. Type llama3:latest for ChatCompletionsModel in config form (hit Enter to add this as a new option and select it from dropdown). You can now type fill Content field in user message and click on Run to see the response from the llama3 model served by Ollama.
Build Recipe Generator App
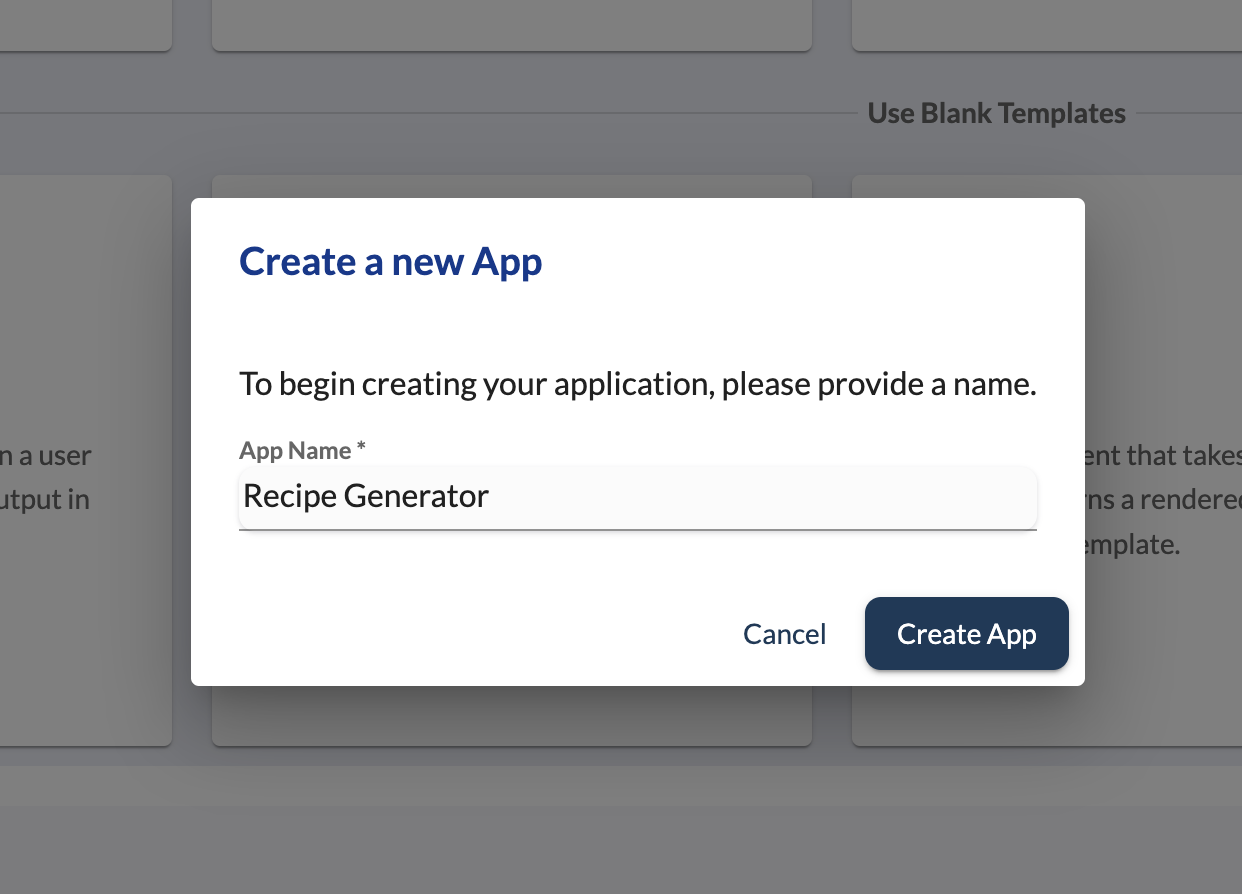
Navigate to the Apps section in Promptly / LLMStack and create a new blank Chat Bot app by clicking on the Chat Bot blank template. Give a name to your app and click on Create App.
Add Input Fields
Add a input field of type string with name Input and a description to take input from the user. This input will be used to generate the recipe.
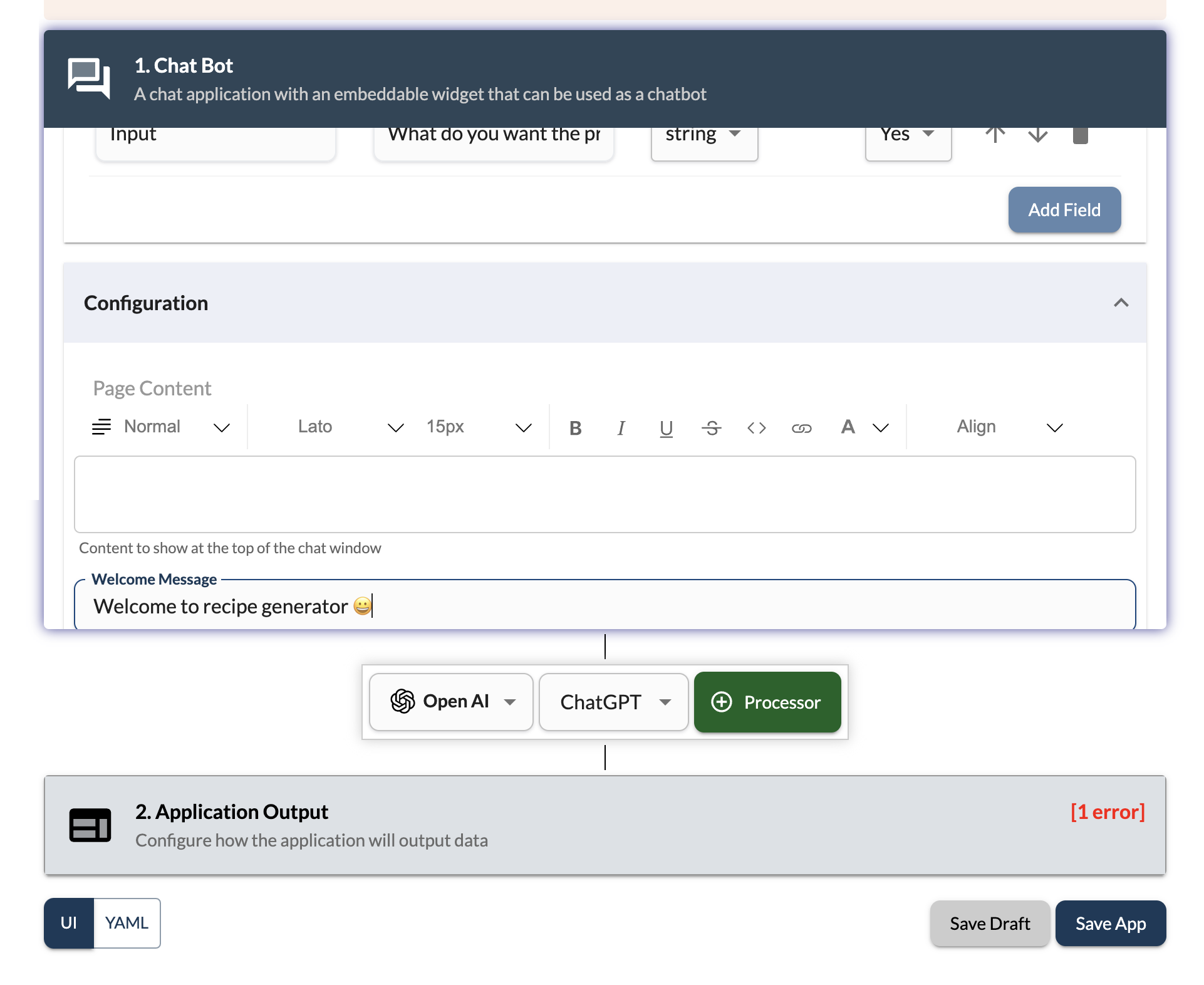
In Configuration section, you can add optional welcome message to greet the user when they open the app.
Add ChatGPT Processor
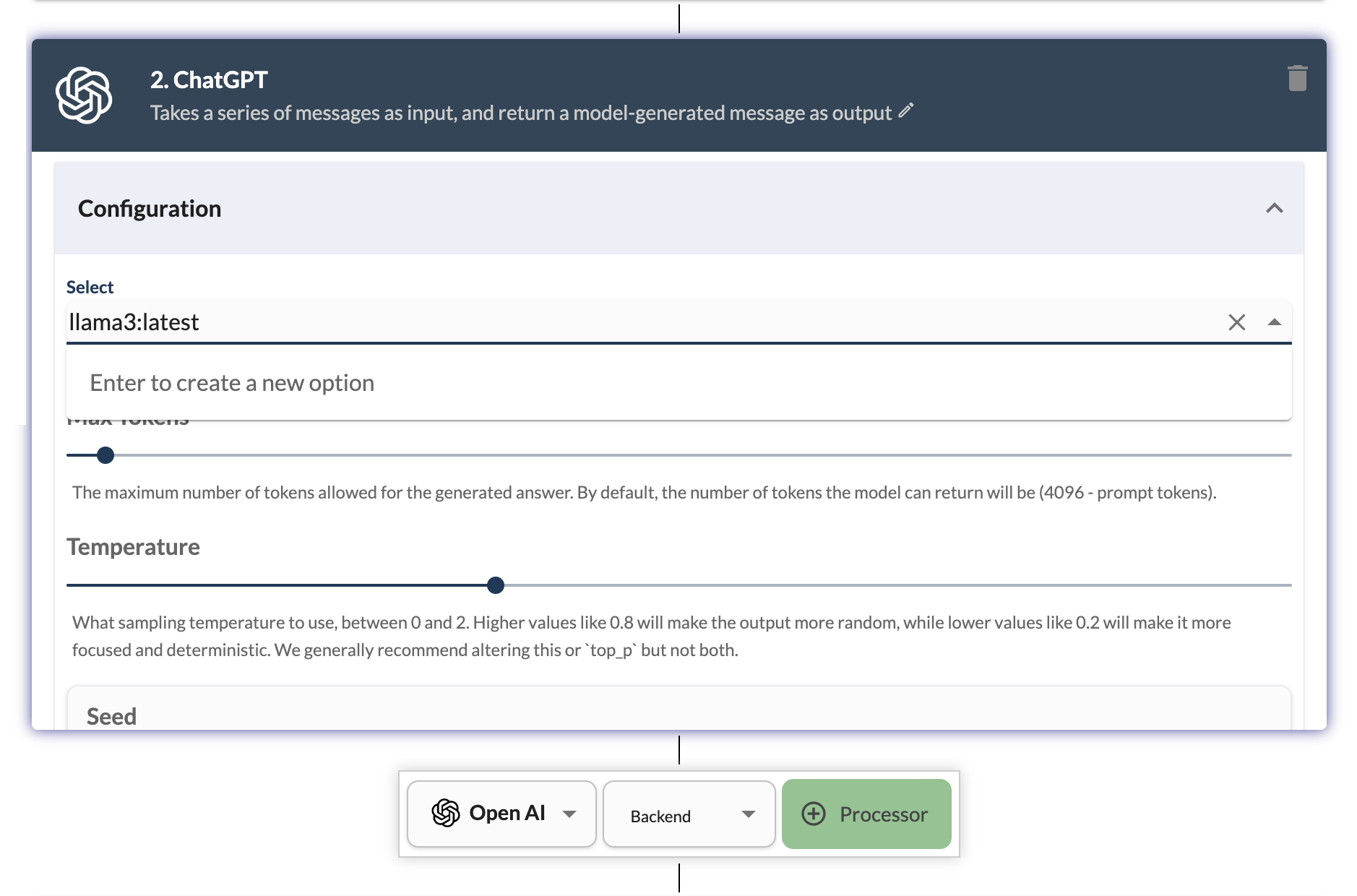
Add a ChatGPT processor to the app and configure it to use the llama3:latest model from Ollama. You can use the OpenAI provider and ChatGPT processor and click on + Processor button. For content field in user message, select the input field using the templates dropdown.
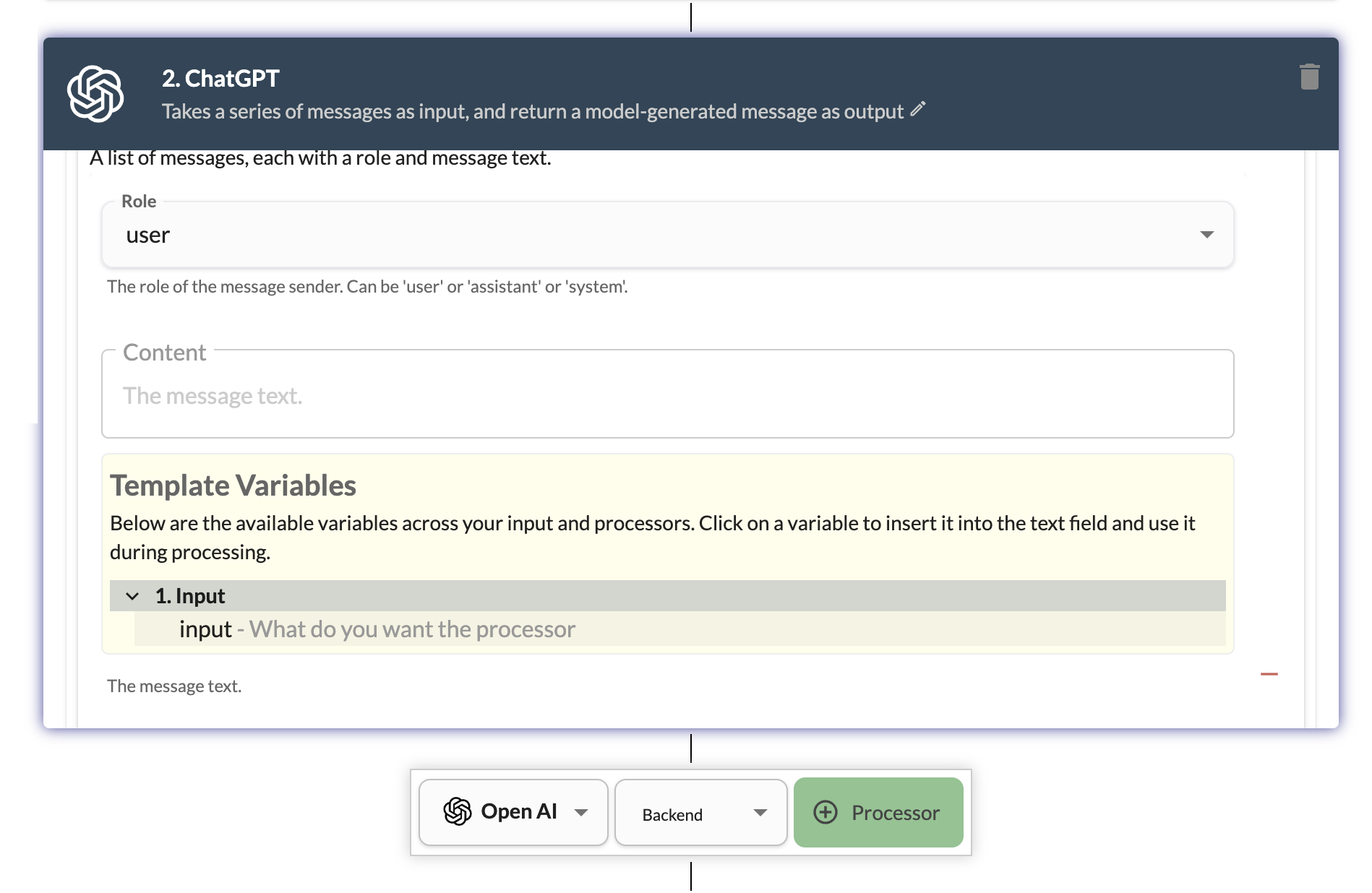
In configuration, add a system message giving a persona ("You are a recipe generator" is a good start). For the model, type llama3:latest and hit enter to add it as a new option. Select the llama3:latest from the dropdown. Select Retain History in configuration to retain the history of the conversation. Select Auto Prune Chat History in advanced configuration to automatically prune the chat history after max tokens is reached.
Configure Output
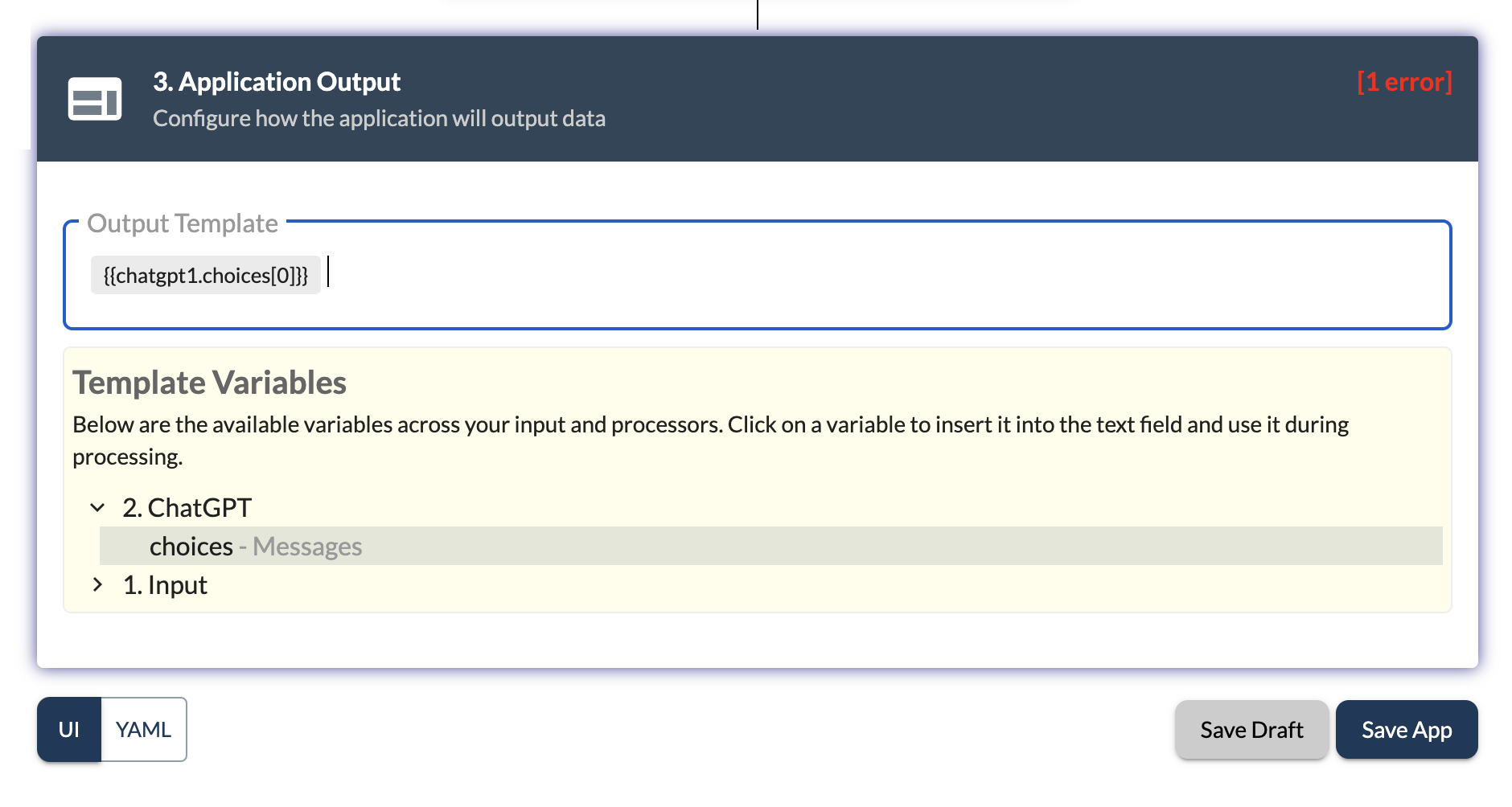
In the output section, you can select the output from the previous processors to be displayed to the user. You can select the ChatGPT processor to display the generated message to the user. Use {{chatgpt1.choices[0].content}} to display the generated recipe from the llama3 model.
Save and Preview
Click on Save Draft button and then go to Preview from the sidebar to see the app in action. You can input a recipe request in the input box and hit enter to see the recipe generated by the llama3 model on Ollama.
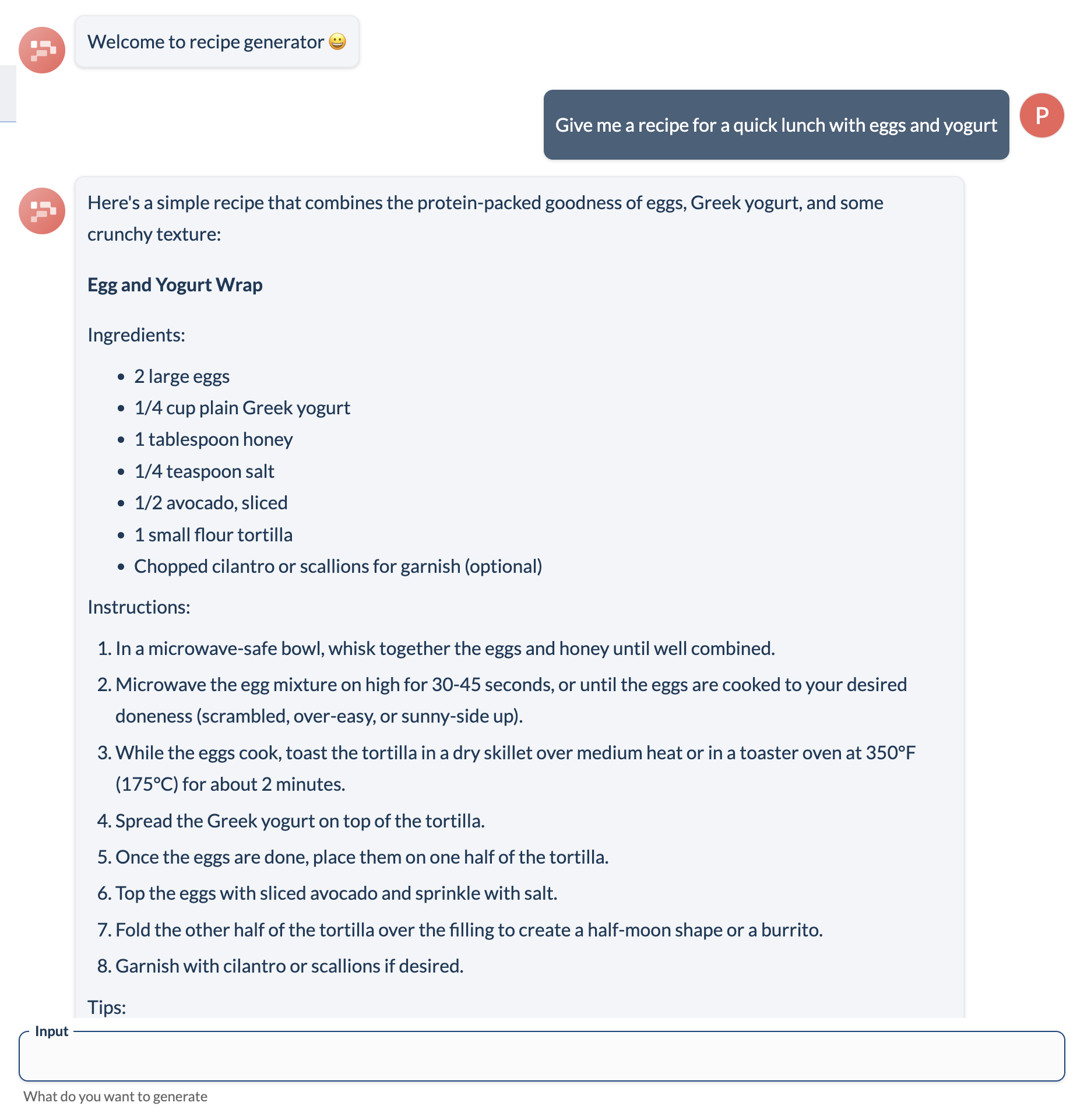
To verify that the completions are being served by llama3 model, you can check the output in ~/.ollama/logs/server.log. You can see the requests to ollama server in the log file once the output is fully generated.
You can also publish the app and share the link with your friends and colleagues to show them the recipe generator app.
By following the above steps, you can build generative AI applications using Ollama and Llama3 on Promptly / LLMStack. You can use this setup to build a variety of generative AI applications like chatbots, code generators, and more.